Current step
This animation visualizes iterative greedy view sampling.
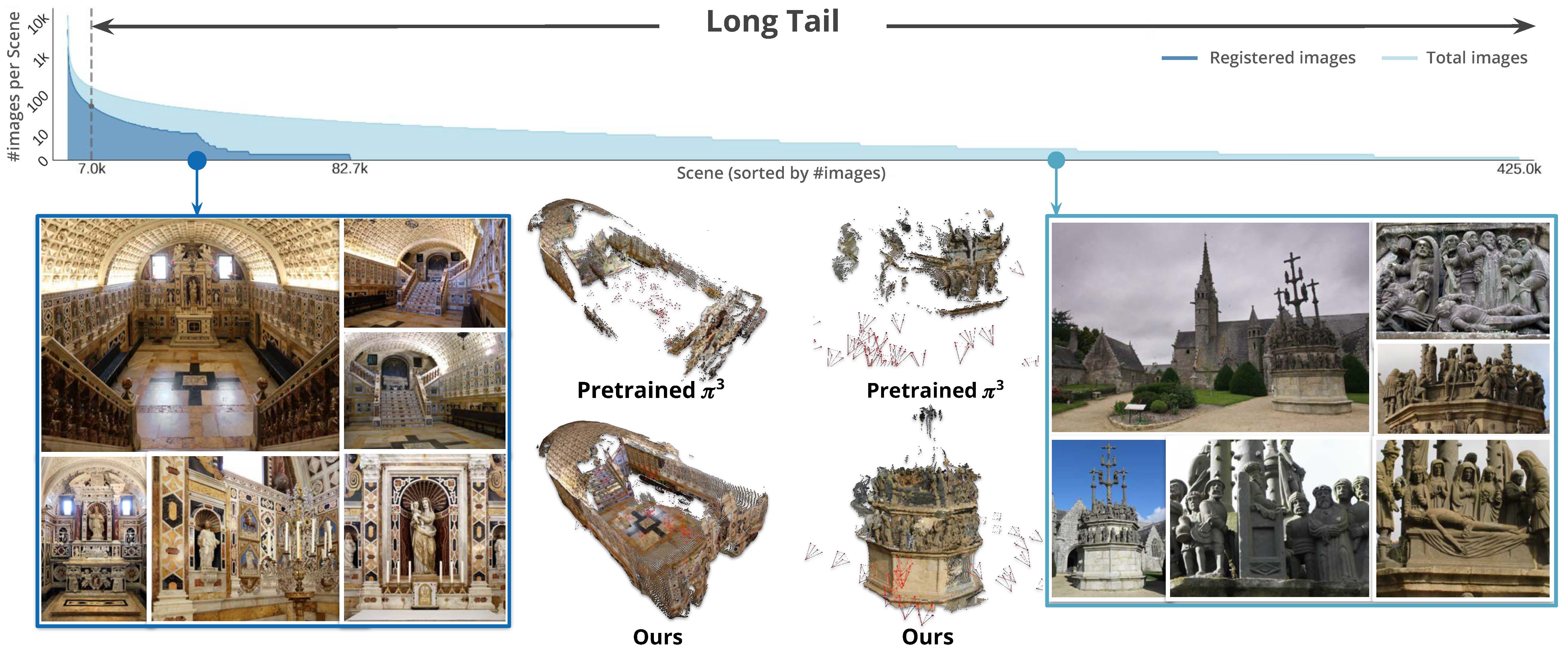
TL;DR: We go beyond densely captured imagery to train more general 3D foundation models for the long tail of noisy, sparse, incomplete Internet photo collections of 3D scenes. We achieve this through MegaDepth-X, a large new dataset of scenes with high-quality 3D supervision, and a new way of simulating difficult image sets for training.
Internet photo collections exhibit an extremely long-tailed distribution: a few famous landmarks are densely photographed and easily reconstructed in 3D, while most real-world sites are represented with sparse, noisy, uneven imagery beyond the capabilities of both classical and learned 3D methods. We believe that tackling this long-tail regime represents one of the next frontiers for 3D foundation models. Although reliable ground-truth 3D supervision from sparse scenes is challenging to acquire, we observe that it can be effectively simulated by sampling sparse subsets from well-reconstructed Internet landmarks. To this end, we introduce MegaDepth-X, a large dataset of 3D reconstrucions with clean, dense depth, together with a strategy for sampling sets of training images that mimic camera distributions in long-tail scenes. Finetuning 3D foundation models with these components yields robust reconstructions under extreme sparsity, and also enables more reliable reconstruction in symmetric and repetitive scenes, while preserving generalization to standard, dense 3D benchmark datasets.
Learning in the long-tail regime requires high-quality 3D supervision derived from Internet photo collections. Our data pipeline combines MASt3R-SfM together with Doppelgangers++, which reconstructs ambiguity-heavy scenes more reliably than COLMAP, especially under repetitive structures and challenging viewpoint distributions. We then run multi-view stereo (MVS) with COLMAP to obtain dense depth maps, followed by post-processing to further refine depth quality.

We also manually verify reconstructed scenes against external references (e.g., Google Maps and Google Earth), and discard any scene that does not align with the corresponding bird's-eye-view geometry. All four examples shown here are bad SfM reconstructions: in (a), non-static human motions cause SfM to fail; in (b) and (c), inconsistent objects dominate the images; and in (d), reconstruction is degraded by doppelganger ambiguities.

After this filtering stage, we eventually curate MegaDepth-X, which is substantially larger than the commonly used in-the-wild reconstruction dataset, MegaDepth.
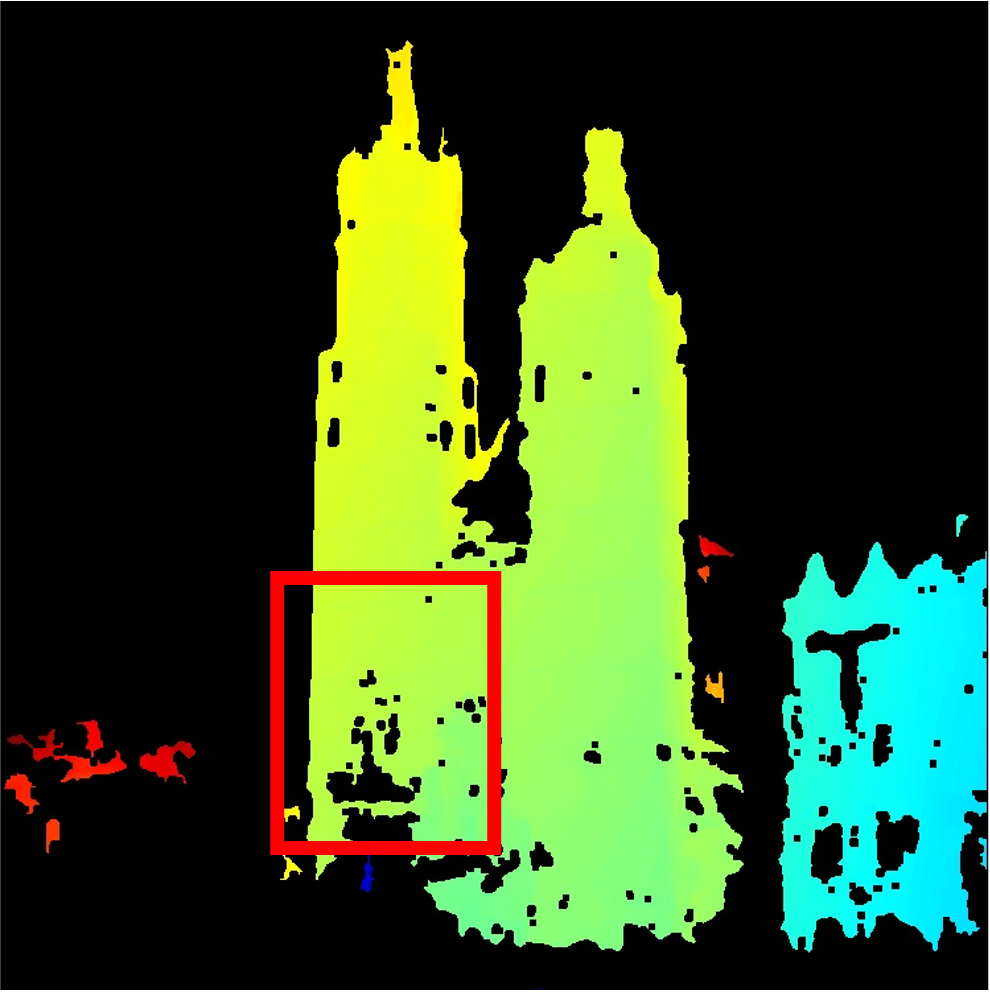
We refine MVS depth maps to filter out inaccurate depth estimates. In the first row (red box), our filtering mitigates Depth bleeding occurs when background depth is incorrectly assigned to foreground pixels. . In the second row, around the hanging light strings in the sky, our filtering removes bad depth caused by transient objects, producing cleaner depth than MegaDepth filtering.





Reliable long-tail supervision is scarce, so direct training in this regime is limited. We therefore simulate long-tail training batches by sampling sparse views from dense SfM reconstructions. Our sampling strategy aims to select views that span diverse viewpoints, maintain sparse overlap to emulate wide-baseline long-tail conditions, and still preserve sufficient covisibility within each scene component.
The panel below visualizes this sampling process with iterative
greedy view sampling. For each training batch, we sample two
disconnected view groups from a single scene graph to simulate two
disjoint scene components, with eight views in each group.
What's in the animation:
• SfM point clouds;
• Camera communities (each community is a camera-view group with dense internal covisibility; small faded cameras in different colors indicate different communities);
• The sampled view at each iteration (highlighted with a red-framed camera);
• Covisibilities between sampled camera pairs (black lines);
• Faded graph edges representing the Steiner tree (the minimal connectivity subgraph).
We compare pretrained baselines and sparse-aware finetuned models for both π³ and VGGT on our curated evaluation set with two difficulty levels (easy and hard). Overall, finetuned models consistently outperform their pretrained counterparts, with larger gains on harder, sparser scenes. Metric definitions and evaluation protocol follow π³.
In this section, we show model predictions on randomly selected long-tail scenes from the MegaScenes dataset, where COLMAP fails to register any images. We present 18 scenes in total, with 2 scenes per page.
For each scene, we show input images, multi-view renderings from pretrained π³ and ours, and Google Earth top-down reference in a single row. Note For a fair comparison, pretrained π³ and ours use the same confidence threshold in each scene. We also discard predicted camera views that contain too many low-confidence pixels.
As shown in the results, our method predicts denser reconstructions and is more robust than the pretrained model in sparse-view scenes, textureless environments, lighting variations, doppelganger ambiguities, and noisy input batches.
This work was supported in part by the Institute of Information & Communications Technology Planning & Evaluation (IITP) grant funded by the Korean Government (MSIT) (No. RS-2024-00457882, National AI Research Lab Project). We thank Joseph Tung, Yiwen Zhang, Hanyu Chen and Haian Jin for discussion and help with MegaScenes dataset and depth post-processing.
@inproceedings{li2026longtail,
title={Long-Tail Internet Photo Reconstruction},
author={Li, Yuan and Xiangli, Yuanbo and Averbuch-Elor, Hadar and Snavely, Noah and Cai, Ruojin},
booktitle={Proceedings of the IEEE/CVF Conference on Computer Vision and Pattern Recognition},
year={2026}
}
Reference: Website template reference: Nerfies.